DAG[func_node_name] and DAG[func_node_out]? #42
Description
A DAGs getitem doesn't return a single FuncNode when I ask for it via its (unique) out or its (unique) name (i.e. func_id).
Is there any reason it shouldn't?
import qo
from meshed import code_to_dag
@code_to_dag
def audio_anomalies():
wf = get_audio(audio_source)
model = train(learner, wf)
results = apply(model, wf)
audio_anomalies.dot_digraph()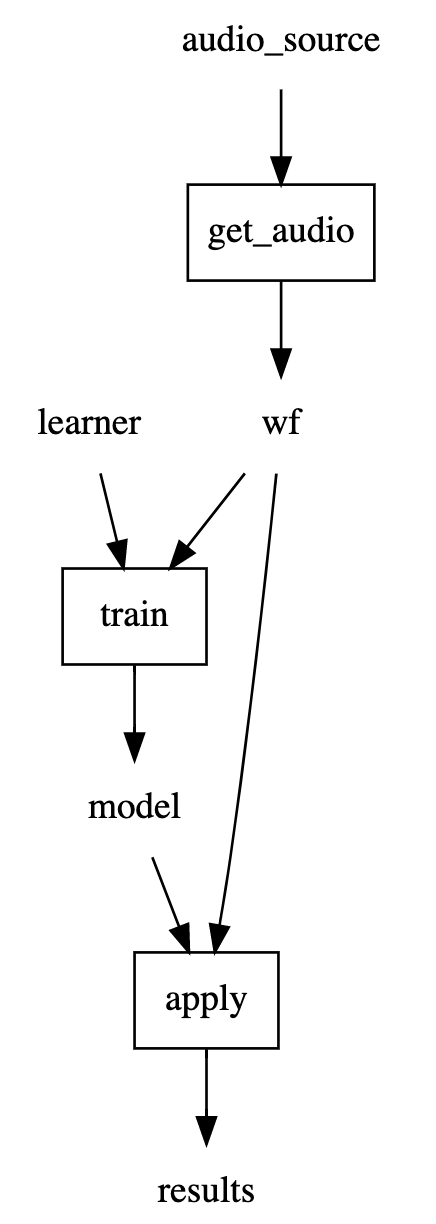
audio_anomalies['wf']
# or (should give the same thing):
audio_anomalies['get_audio']---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
/var/folders/19/3fn2895s5hng3n7418fqs6w40000gn/T/ipykernel_21931/314640200.py in <module>
----> 1 audio_anomalies['get_audio']
~/Dropbox/py/proj/i/meshed/meshed/dag.py in __getitem__(self, item)
724
725 """
--> 726 return self._getitem(item)
727
728 def _getitem(self, item):
~/Dropbox/py/proj/i/meshed/meshed/dag.py in _getitem(self, item)
728 def _getitem(self, item):
729 return DAG(
--> 730 func_nodes=self._ordered_subgraph_nodes(item),
731 cache_last_scope=self.cache_last_scope,
732 parameter_merge=self.parameter_merge,
~/Dropbox/py/proj/i/meshed/meshed/dag.py in _ordered_subgraph_nodes(self, item)
734
735 def _ordered_subgraph_nodes(self, item):
--> 736 subgraph_nodes = self._subgraph_nodes(item)
737 # TODO: When clone ready, use to do `constructor = type(self)` instead of DAG
738 # constructor = type(self) # instead of DAG
~/Dropbox/py/proj/i/meshed/meshed/dag.py in _subgraph_nodes(self, item)
742
743 def _subgraph_nodes(self, item):
--> 744 ins, outs = self.process_item(item)
745 _descendants = set(
746 filter(FuncNode.has_as_instance, set(ins) | descendants(self.graph, ins))
~/Dropbox/py/proj/i/meshed/meshed/dag.py in process_item(self, item)
821
822 def process_item(self, item):
--> 823 assert isinstance(item, slice), f'must be a slice, was: {item}'
824
825 input_names, outs = item.start, item.stop
AssertionError: must be a slice, was: get_audio
Possible Solution
k -> k:k
If in dag[k], k is not a slice, change to k?
Would be okay, but only works when k is a FuncNode name, not an out.
>>> audio_anomalies['get_audio':'get_audio']
DAG(func_nodes=[FuncNode(audio_source -> get_audio -> wf)], name=None)
But
>>> audio_anomalies['wf':'wf']
DAG(func_nodes=[], name=None)
On the other hand, name:out works:
>>> audio_anomalies['get_audio':'wf']
DAG(func_nodes=[FuncNode(audio_source -> get_audio -> wf)], name=None)
Is there any reason we want an out:out (e.g. 'wf':'wf') to be an empty DAG, but not name:name (e.g. 'get_audio':'get_audio'?
Interpreting start:end with end being non-inclusive is consistent with list slicing, so that's a good thing.
But then, name:name should perhaps be consistent with that too.
a bit more work
The k -> k:k is clean and maximizes reuse, but we don't have to do that much more work to get the behavior we want.
We can easily condition that rule based on if k is a FuncNode or VarNode. Simply like so, if k is the name of a FuncNode fn, change to name:fn.out and if it's an out of a FuncNode fn, change to fn.name:out.
The real question here is: Are we creating complexity because of a bad design -- the inconsistency mentioned above -- or is the design choices mentioned above a good one?
Or do we NOT want to have DAG[...] deal with anything than slices in the first place?