inputs: sample.sam, sample.gtf
Usage:
- place py in a directory with your sample.sam and sample.gtf
- run with python (i.e
$python Sam2tpm_rpkm.py)
How it works:
###Calculate TPM:
![(X[i]/L[i])*(1/(sum(Xtot/Ltot)))*1e6](https://s0.wp.com/latex.php?latex=%5Ctext%7BTPM%7D_i+%3D+%5Cdfrac%7BX_i%7D%7B%5Cwidetilde%7Bl%7D_i%7D+%5Ccdot+%5Cleft%28+%5Cdfrac%7B1%7D%7B%5Csum_j+%5Cdfrac%7BX_j%7D%7B%5Cwidetilde%7Bl%7D_j%7D%7D+%5Cright%29+%5Ccdot+10%5E6&bg=ffffff&fg=000000&s=0)
(X[i]/L[i])*(1/(sum(Xtot/Ltot)))*1e6####breaking it down to steps:
- Take each gene read and divide by length (in kb) of gene
- Next take these normalized reads and sum them for each gene
- create scaling factor by dividing summed normalized reads by 1e6
- take your normalized reads from step 1 and divide by the scaling factor
####Taken from these websites: Instructions from [here] (https://www.youtube.com/watch?v=TTUrtCY2k-w) and [here] (https://haroldpimentel.wordpress.com/2014/05/08/what-the-fpkm-a-review-rna-seq-expression-units/)
###Calculate RPKM:
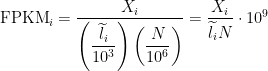
Mapped_Reads/((Total_reads/1000000) * (Lenth_Gene/1000))#####Mapped_Reads is the reads that were mapped to a gene in the gtf file #####Total_reads is the total reads in the experiment #####Length of gene is in kb
- Get number of reads
- Calculate Number_of_reads/(length_of_gene/kilobase * total_number_reads/1e6)
Instructions found here
##How to use:
Run it in the command line as such:
$python SamToTpm.py
Input: Input sam file must be named: "sample.sam" Input gtf file must be named: "sample.gtc"
Example sam:
@HD VN:1.3 SO:coordinate
@SQ SN:reference LN:5528445
HWI-ST1426:114:HGTH7ADXX:1:1202:2398:51916 163 reference 4 60 101M = 37 134 TTTTCATTCTGACTGCAACGGGCAATATGTCTCTGTGTGGATTAAAAAAAGAGTCTCTGACAGCAGCTTCTGAACTGGTTACCTGCCGTGAGTAAATTAAA BBBFFFFFFFFFFIIIIIIIIIIIIIIIFIFIIIIFFFFIIIFFIIIIIIIIIIIIIIFFFFFFFFFFFFFFFFBFFFFFFFFFFFFFBFFF<BBBFFFFF XT:A:U NM:i:0 SM:i:37 AM:i:37 X0:i:1 X1:i:0 XM:i:0 XO:i:0 XG:i:0 MD:Z:101
HWI-ST1426:114:HGTH7ADXX:1:1216:11691:62785 99 reference 11 29 35S24M42S = 35 101 GGCAATATGTCTCTGTGTGGATTAAAAAAAGAGTCTCTGACTGCAACGGGCAATATGTCTCTGTGTGGATTAAAAAAAGAGTCTCTGACAGCAGCTTCTGA BBBFFFFFFBBFBFFFFFFFFFFFBF<BFIFFFBFIFFFFFFIFIFIIII<FFFFIIFBFFFFBFBFFFBFBBB<77BBBFFBBBBBFBFF<BBFFBBBBB XT:A:M NM:i:0 SM:i:29 AM:i:29 XM:i:0 XO:i:0 XG:i:0 MD:Z:24
HWI-ST1426:114:HGTH7ADXX:1:2203:7459:45734 117 reference 16 0 * = 16 0 TCAGAAGCTGCTGTCAGAGACTCTTTTTTTAATCCACACAGAGACATATTGCCCGTTGCAGTCAGAGACTCTTTTTTTAATCCACACAGAGACATATTGCC BB<<FB<BBBBBBBBFFBBBBB<7BB<BBBBB<FFBBBBB7<<<FFIIIIIFBFFFFBFIIFBFBFFFIIIFFBFIFFFFBFFFFFIIFFBFFFFFFFBBB
HWI-ST1426:114:HGTH7ADXX:1:2203:7459:45734 153 reference 16 37 54M = 16 0 CTGCAACGGGCAATATGTCTCTGTGTGGATTAAAAAAAGAGTCTCTGACAGCAG BB<BBB<BB<<BBBBBBBBB<<BFBBBBFB<FBFIIFFFFFFFFIFFFFFFB77 XT:A:U NM:i:0 SM:i:37 AM:i:0 X0:i:1 X1:i:0 XM:i:0 XO:i:0 XG:i:0 MD:Z:54
HWI-ST1426:114:HGTH7ADXX:1:1203:18673:44805 99 reference 22 60 101M = 126 205 CGGGCAATATGTCTCTGTGTGGATTAAAAAAAGAGTCTCTGACAGCAGCTTCTGAACTGGTTACCTGCCGTGAGTAAATTAAAATTTTATTGACTTAGGTC BBBFFFFFFFFFFFIIIIIFFIBFFIFFIIIIIIIIIIIFFFIIIIIFIFFIIIBBFFFFIIIFFFFFFFFFBBBBBFFFBBFFFFFFFFFBBFBFFFFBB XT:A:U NM:i:0 SM:i:37 AM:i:37 X0:i:1 X1:i:0 XM:i:0 XO:i:0 XG:i:0 MD:Z:101
HWI-ST1426:114:HGTH7ADXX:1:2212:5218:9001 163 reference 22 60 101M = 126 205 CGGGCAATATGTCTCTGTGTGGATTAAAAAAAGAGTCTCTGACAGCAGCTTCTGAACTGGTTACCTGCCGTGAGTAAATTAAAATTTTATTGACTTAGGTC BBBFFFFFFFFFFIIIIFIIIIIIIIIIIIIIIIIFIIIIIIIIIIIIIIIIIIIIIIIIFIIFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFBFFFBB XT:A:U NM:i:0 SM:i:37 AM:i:37 X0:i:1 X1:i:0 XM:i:0 XO:i:0 XG:i:0 MD:Z:101
HWI-ST1426:114:HGTH7ADXX:1:1107:18270:12891 163 reference 23 60 101M = 73 151 GGGCAATATGTCTCTGTGTGGATTAAAAAAAGAGTCTCTGACAGCAGCTTCTGAACTGGTTACCTGCCGTGAGTAAATTAAAATTTTATTGACTTAGGTCA BBBFFFFFFFFFFIIIFIFIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF XT:A:U NM:i:0 SM:i:37 AM:i:37 X0:i:1 X1:i:0 XM:i:0 XO:i:0 XG:i:0 MD:Z:101
HWI-ST1426:114:HGTH7ADXX:1:1211:11146:4928 99 reference 23 60 101M = 73 151 GGGCAATATGTCTCTGTGTGGATTAAAAAAAGAGTCTCTGACAGCAGCTTCTGAACTGGTTACCTGCCGTGAGTAAATTAAAATTTTATTGACTTAGGTCA BBBFFFFFFFFFFIIIFIFFFIIIIIIIIIIIIIFFFIIIIIIIIIFIIIIIIIIIIIIFIFIIIFFFFFFFFFBFFFFFFFBFFBFFFFBFFFFFFFBFF XT:A:U NM:i:0 SM:i:37 AM:i:37 X0:i:1 X1:i:0 XM:i:0 XO:i:0 XG:i:0 MD:Z:101
sample gtc file:
reference CDS 10 104 . + 1 something
reference CDS 114 281 . + 1 something
Output: The output will come in the command line:
Example:
Gene: 'reference', Feature: 'CDS', TPM: 42711772.175, RPKM: 2417794.971
Gene: 'reference', Feature: 'CDS', TPM: 91118447.306, RPKM: 2903284.34