Bu repoda görüntü işleme dersinde verilen ödevler ve yapılan projeler bulunmaktadır.
Görüntülere smoothing ve edge detection fitreleri uygulanarak görüntüler üzerindeki değişimler incelenmiştir. Bu kısımda bahsedilen her şeyin implementasyonu C dilinde gerçekleştirilmiş olup Image-Filtering klasörü içerisine eklenmiştir.
Image filtering klasörü içerisinde yer alan kodda ilk olarak .pgm formatındaki görüntüler okunur. Okunan görüntüler üzerine seçilen bir yumuşatma filtresi uygulanır. Yumuşatma filtreleri (smoothing filters) resimlerdeki gürültüleri (noise) gidermek için kullanılırlar ve bu filtrelerden biri de Gaussian filtresidir. Kodda gerçekleştirilen Guassian filtrelerinin boyutları 3x3, 5x5 ve 7x7 seçilip sigma(σ) değerleri ise 1.0, 2.0 ve 4.0 seçilerek farklı filtre boyutları ve sigma değerlerinde elde edilen görüntüler karşılaştırılmıştır. Filtre boyutu ve σ değerleri artıkça resimlerin bulanıklığının arttığı görülmüştür. Burada dikkat edilmesi gereken bulanıklaştırmanın kenar tespitini engelleyecek kadar fazla olmamasıdır.
Parametrelerin etkisinin bir örneği aşağıda görülmektedir:
Boyut: 7x7 ve σ: 1.0

Boyut 7x7 ve σ: 4.0

Gaussian filtresinin uygulanmasından sonraki aşama kenar algılama (edge detection) filtrelerinin uygulanmasıdır. Kenar algılama filtrelerinin yumuşatma işleminden sonra kullanılmasının nedeni algılamayı kötü yönde etkileyen gürültüyü önlemektir. Kenar algılama filtrelerine örnek olarak Sobel ve Laplacian filtreleri verilebilir. Bu filtrelerden Sobel filtresi incelenerek görselleri aşağıda verilmiştir. Kodda uygulanan Sobel filtreleri şekildeki gibidir:
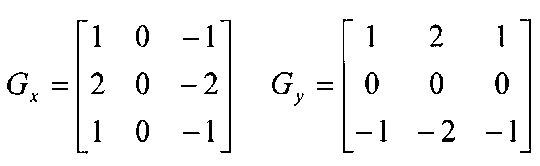
Sobel filtresi sonucu elde edilen x ve y yönündeki kenarlar da aşağıdaki şekillerdeki gibidir:
Sobel X => Dikey yöndeki kenarları algılar.

Sobel Y => Yatay yöndeki kenarları algılar.

Buradakilerin haricinde başka yumuşatma ve kenar algılama filtreleri de bulunmaktadır. Bu gibi işlemler görüntü işlemenin temellerini oluşturmaktadır. Yumuşatma ve kenar filtreleri için aşağıdaki link incelenebilir:
https://sbme-tutorials.github.io/2018/cv/notes/4_week4.html
Doku analizinde Uniform Local Binary Pattern(ULBP) algoritmasının implementasyonu Python dilinde gerçekleştirilmiştir. Texture-Analysis klasöründen kodu inceleyebilirsiniz.
Bilgisyarınızda Python 3.x versiyonu ve Spyder ya da Pycharm kurulu olmalıdır.
- Opencv
- Numpy
- Matplotlib
- Os
Doku dediğimiz şey aslında tekrar eden bilgi olarak açıklanabilir. Doku analizinde birçok yöntem (Gray level co-occurance matrix, Law's texture energy maps, Local binary patterns vb.) olmakla birlikte bu kısımda incelenen Uniform Local Binary Pattern yöntemidir. Uniform Local Binary Pattern temel olarak görüntüler üzerinde 3x3 boyutunda bir kernel ile baştan sona gezerek merkez pixel ile komşu pixelleri karşılaştırır. Eğer çevre piksel değerleri merkez piksel değerinden büyükse 1 küçükse 0 olarak atama yapılır ve bunun sonucunda her kernel için 8 bitlik bir değer elde edilir. Bu 8 bitteki bit değişimleri 2’den büyükse burada anlamlı bir örüntü yoktur denerek bu şekilde çıkan bütün 8 bitlik değerler tek bir onluk tabandaki değere atanır. Bu değer bizim kodumuzda 51 olarak belirlenmiştir. Eğer bit değişimleri 2'den küçükse o zaman 8 bitlik değer onluk tabana çevrilir ve elden edilen değer ne ise o şekilde saklanır. Bu aşamanın sonunda resimler için ULBP değerlerinden oluşan yeni matrisler elde edilmiş olur. ULBP sonucu oluşan her bir matris histogramları hesaplanmak üzere histogram fonksiyonuna gönderilir. Her bir resim için elde edilen histogramlar normalize edilir ve bu histogramlar saklanır. Bu işlemler hem test kalsöründeki hem de train kalsöründeki resimler için gerçekleştirilir. En sonunda ise her bir test resmi ile bütün train resimlerinin histogramları karşılaştırılarak seçilen test resmine en benzer 3 tane train resmi elde edilir.
Aşağıda bir test resmi için en benzer 3 adet train resminin olduğu görseller verilmiştir ve altlarına da benzerlik oranları eklenmiştir.
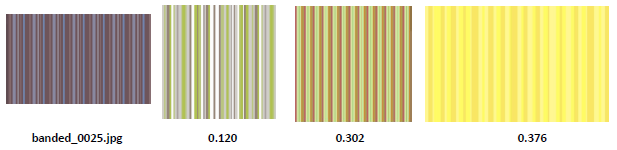



Resimlerde görüldüğü gibi bazı dokularda tam başarı sağlarken bazı dokularda ise hiç bulamayabilmektedir. Daha detay için Texture-Analysis klasörü içerisindeki rapora bakılabilir ve ayrıca LBP ile ilgili aşağıdaki kaynak incelenebilir.
https://pyimagesearch.com/2015/12/07/local-binary-patterns-with-python-opencv/
Konvolüsyonel sinir ağları(CNN) ile CIFAR-10 veri kümesi üzerinde sınıflandırma işlemi gerçekleştirilmiştir. CIFAR-10_CNN klasöründen kodu ve raporu inceleyebilirsiniz.
Bilgisyarınızda Python 3.x versiyonu ve Jupyter Notebook kurulu olmalıdır. Ayrıca colab notebook üzerinde de çalışılabilir.
- Numpy
- Matplotlib
- Sklearn
- Tensorflow
CIFAR-10 veri seti 32x32 boyutunda renkli resimlerden oluşmaktadır. 10 farklı sınıf mevcut olan veri setinde toplam 60000 adet resim mevcuttur. CNN yapısı ile bu 10 farklı sınıf üzerinden sınıflandırma yapılmıştır. Bu kısımda bir sinir ağı oluşturmak için birçok hiperparamtre mevcuttur. Bunlardan bazıları konvolüsyon katman sayısının belirlenmesi, konvolüsyon katmanındaki filtre sayısı ve kernel büyüklüğünün belirlenmesi, aktivasyon fonksiyonu seçimi, dropout eklenmesi ve katmanların hangi sırayla dizilecekleri şeklinde belirtilebilir. Kod içerisinde bu gibi farklı farklı parametreler denenerek en yüksek validation başarısı olan CNN yapısı belirlenmiş olup aşağıdaki görselde bu yapı özetlenmiştir.

Aktivasyon fonksiyonu olarak ReLu kullanılıp katmanların arasına batch normalization işlemi eklenmiştir. Bu model test veri seti ile test edildiğinde %84.1'lik bir sınıflandırma başarısı elde edilir. Son olarak bazı örnek resimler üzerinde hem o resimlerin gerçek sınıfları hem de modelin tahmin ettiği en yüksek başarıya sahip 5 sınıf gösterilmiştir. Bazı örnekler aşağıdan incelenebilir.

CNN yapısı için konvolüsyon işlemi nasıl oluyor ya da katmanlarda neler gerçekleşiyor gibi sorular için Andrew Ng'nin youtube üzerindeki bu serisi takip edilebilir.
https://www.youtube.com/watch?v=ArPaAX_PhIs&list=PLkDaE6sCZn6Gl29AoE31iwdVwSG-KnDzF
Ayrıca yine CNN katmanlarıyla ilgili bilgiler için linkteki medium yazısı da incelenebilir.
Bu çalışmada LinkNet mimarisi kullanılarak Oxford-IIIT Pet veri seti üzerinde bir semantik segmentasyon işlemi gerçekleştirilmiştir. Veri setine https://www.robots.ox.ac.uk/~vgg/data/pets/ linkinden erişebilirsiniz ya da Tensorflow Dataset içerisinde hazır olarak bulunan halini yükleyebilirsiniz. Ek olarak Image-Segmentation klasöründen semantik segmentasyon kodunu ve açıklamaların olduğu raporu inceleyebilirsiniz.
Bilgisyarınızda Python 3.x versiyonu ve Jupyter Notebook kurulu olmalıdır. Ayrıca colab notebook üzerinde de çalışılabilir.
- Numpy
- Matplotlib
- Pandas
- Tensorflow
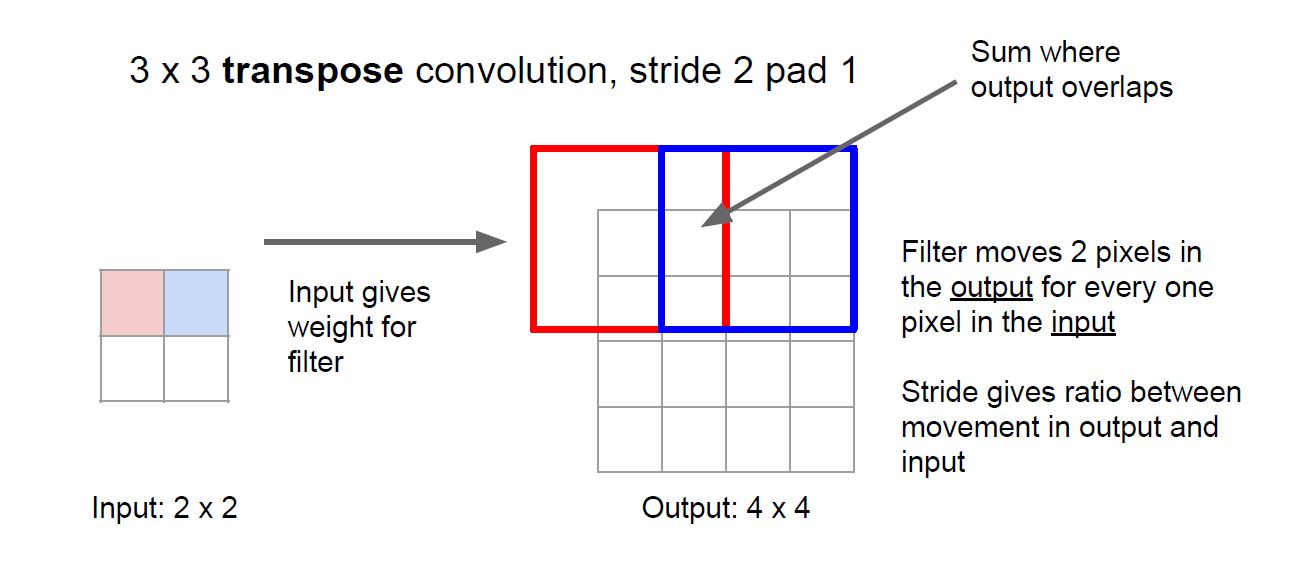
Oxford-IIIT Pet veri seti 37 farklı sınıftan oluşan evcil hayvan görselleri, etiketleri ve piksel bazında maskeleri içermektedir. Bu veri seti üzerinde encoder decoder şeklindeki LinkNet mimarisi ile semantik segmentasyon işlemi gerçekleştirilmiştir. Encoder yapısı görüntüyü alıp yüksek boyutlu özellik vektörlerine çeviriken decoder yapısı ise bu özellik vektörlerini alarak bir semantik segmentasyon maskesi oluşturmaktadır. LinkNet mimarisi giriş katmanı, encder katmanları, decoder katmanları ve çıkış katmanı olmak üzere 4 kısma ayrılabilir. LinkNet encoder bloğu olarak ResNet18 mimarisini kullanmaktadır. Aslında bu kısım bildiğimiz CNN mimarisi şeklindedir. Ancak decoder kısmına geldiğimizde burada bir deconvolution ya da transpose convolution denilen kavram bulunmaktadır. Transpose convolution işleminde görüntü orijinal haline getirilmketedir ve bu da bir pikselde bulunan bilgi diğerlerine yayılarak yapılmaktadır. Daha iyi anlamak için aşağıdaki gif incelenebilir.

Hem transpose convolution işleminin nasıl yapıldığının daha iyi anlaşılması için hem de semantik segmentasyon için Stanford üniversitesine ait slayt serisi http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture11.pdf linkinden incelenebilir. Bu slaytlardan transpose convolution işlemine ait bir görsel aşağıda verilmiştir. 2x2'lik bir görüntüye 3x3'lük bir transpose convolution işlemi uygulanmıştır. Padding 1 ve stride 2 olacak şekilde deconvolution işlemi gerçekleştirilmiştir.
Hiperparametre değişimi ile birden çok model denenmiştir. Bunlar içerisinden validation başarısı en yüksek model seçilip test setinde üzerinde test edildiğinde %85.56'lık başarı elde edilmiştir. Değerlendirme metrikleri olarak doğrulamanın yanı sıra dice katsayısı kullanılmıştır. Dice katsayısı tahmin edilen segmentasyon ile gorund truth değerleri arasındaki piksel bazında bir karşılaştırmadır. Dice katsayısı değeri 1’e ne kadar yaklaşırsa ground truth değerleri ile tahmin edilen segmentasyon değerleri arasında örtüşme o kadar artar denilebilmektedir. En son mevcut görüntüler, gorund truth ve model tarafından tahmin edilen segmentasyon görselleştirilmiştir.

Genel olarak segmentasyon ile ilgili bilgi edinmek için Stanford Üniveristesi tarafından yayınlanan aşağıdaki youtube linki incelenebilir.
https://www.youtube.com/watch?v=nDPWywWRIRo&t=3143s
LinkNet mimarisinin makalesine aşağıdaki bağlantıdan erişebilirisiniz.
https://arxiv.org/pdf/1707.03718.pdf