Akarsh Kumar
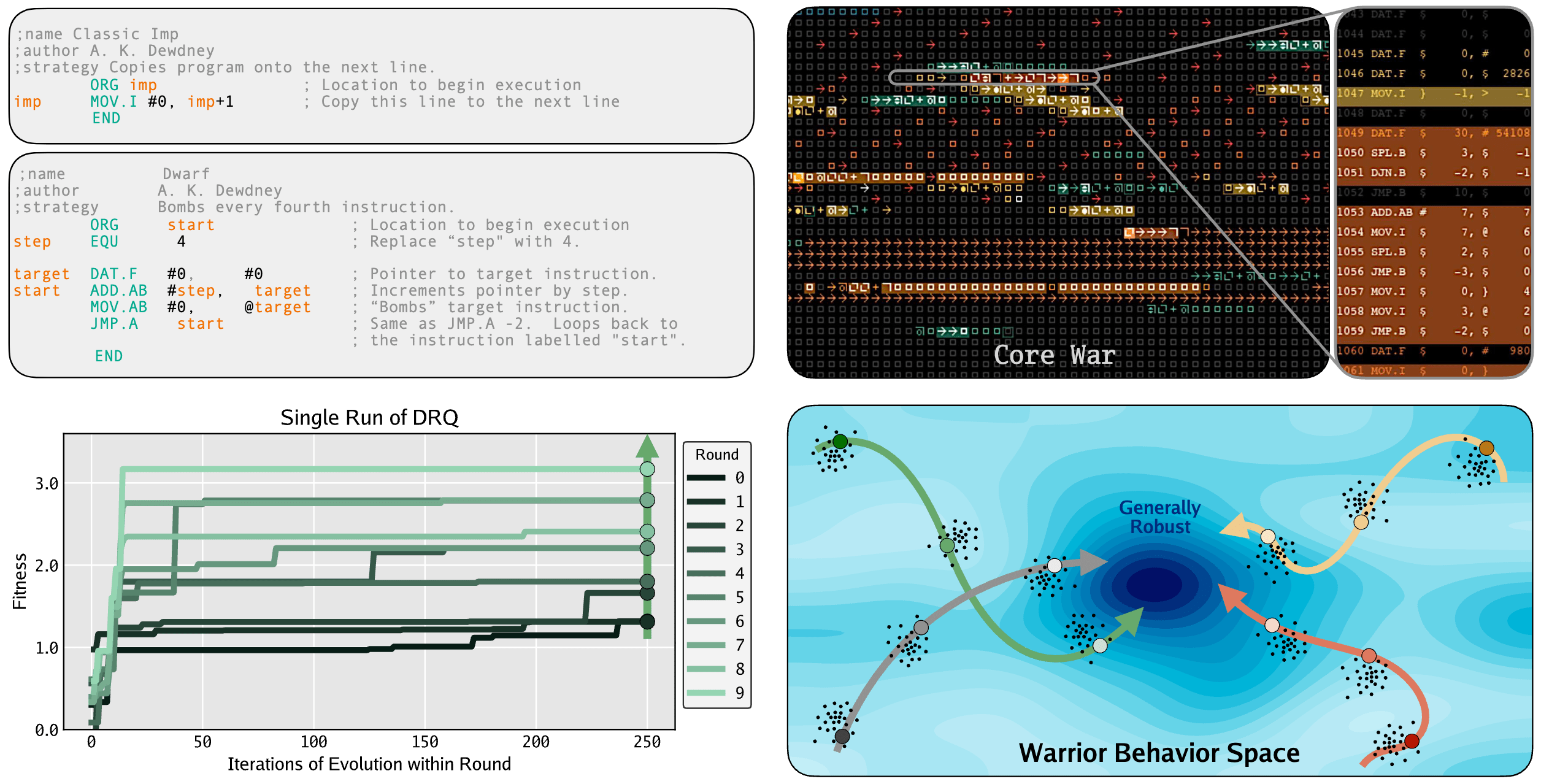
Large language models (LLMs) are increasingly being used to evolve solutions to problems in many domains, in a process inspired by biological evolution. However, unlike biological evolution, most LLM-evolution frameworks are formulated as static optimization problems, overlooking the open-ended adversarial dynamics that characterize real-world evolutionary processes. Here, we study Digital Red Queen (DRQ), a simple self-play algorithm that embraces these so-called "Red Queen" dynamics via continual adaptation to a changing objective. DRQ uses an LLM to evolve assembly-like programs, called warriors, which compete against each other for control of a virtual machine in the game of Core War, a Turing-complete environment studied in artificial life and connected to cybersecurity. In each round of DRQ, the model evolves a new warrior to defeat all previous ones, producing a sequence of adapted warriors. Over many rounds, we observe that warriors become increasingly general (relative to a set of held-out human warriors). Interestingly, warriors also become less behaviorally diverse across independent runs, indicating a convergence pressure toward a general-purpose behavioral strategy, much like convergent evolution in nature. This result highlights a potential value of shifting from static objectives to dynamic Red Queen objectives. Our work positions Core War as a rich, controllable sandbox for studying adversarial adaptation in artificial systems and for evaluating LLM-based evolution methods. More broadly, the simplicity and effectiveness of DRQ suggest that similarly minimal self-play approaches could prove useful in other more practical multi-agent adversarial domains, like real-world cybersecurity or combating drug resistance.
This repo contains a minimalistic implementation of DRQ to get you started ASAP. Everything is implemented in pure Python, with multiprocessing, making it decently fast.
The original Core War code is from https://github.com/rodrigosetti/corewar!
The important code is here:
-
src/drq.py is for running the main DRQ algorithm.
-
src/eval_warriors.py is for evaluating battles between two saved warriors.
-
src/corewar_util.py has helper code to run the Core War simulation.
-
src/llm_corewar.py has code to instantiate an LLM and use it to generate new Core War warriors.
-
corewar/corewar/*.py is the original Core War code from here.
Prompts:
- src/prompts/system_prompt_0.txt has the system prompt for the LLM, containing the specification for Redcode, and some example programs.
- src/prompts/new_prompt_0.txt has the prompt to tell the LLM to generate a new warrior.
- src/prompts/mutate_prompt_0.txt has the prompt to tell the LLM to mutate an existing warrior.
To run this project locally, you can start by cloning this repo.
git clone https://github.com/SakanaAI/drq.gitThen, set up the python environment with conda:
conda create --name drq python=3.12.3
conda activate drqThen, install the necessary python libraries:
python -m pip install -r requirements.txtAlso go ahead and install the corewar library that exists within this repository:
python -m pip install -e corewarHere is some minimal code to load five different human-made warriors and run a battle between them:
from corewar_util import SimulationArgs, parse_warrior_from_file, run_multiple_rounds
simargs = SimulationArgs()
_, warrior1 = parse_warrior_from_file(simargs, "../human_warriors/all_list/imp.red")
_, warrior2 = parse_warrior_from_file(simargs, "../human_warriors/all_list/dwarf.red")
_, warrior3 = parse_warrior_from_file(simargs, "../human_warriors/all_list/burp.red")
_, warrior4 = parse_warrior_from_file(simargs, "../human_warriors/all_list/mice.red")
_, warrior5 = parse_warrior_from_file(simargs, "../human_warriors/all_list/rato.red")
warriors = [warrior1, warrior2, warrior3, warrior4, warrior5]
battle_results = run_multiple_rounds(simargs, warriors, n_processes=24, timeout=100)
print(battle_results['score'].mean(axis=-1))This would print something like:
[0.17974488 0.08946862 0.50905282 1.98734753 2.23438615]
Here is some code to generate a new warrior and mutate an existing warrior using an LLM:
from corewar_util import SimulationArgs, parse_warrior_from_file, run_multiple_rounds, simargs_to_environment
from llm_corewar import CorewarGPT
import asyncio
simargs = SimulationArgs()
system_prompt = "./prompts/system_prompt_0.txt"
new_warrior_prompt = "./prompts/new_prompt_0.txt"
mutate_warrior_prompt = "./prompts/mutate_prompt_0.txt"
with open(system_prompt, "r") as f:
system_prompt = f.read()
with open(new_warrior_prompt, "r") as f:
new_warrior_prompt = f.read()
with open(mutate_warrior_prompt, "r") as f:
mutate_warrior_prompt = f.read()
gpt = CorewarGPT("gpt-4.1-mini-2025-04-14", system_prompt, new_warrior_prompt, mutate_warrior_prompt, temperature=1., environment=simargs_to_environment(simargs))
new_warriors = asyncio.run(gpt.new_warrior_async(n_warriors=1, n_responses=8)).flatten() # get 8 new warriors
new_warriors = [w for w in new_warriors if w is not None and w.warrior is not None]
for w in new_warriors:
print('--------------------------------')
print(w.warrior)
print(w.llm_response)
print(w.warrior)
for i in w.warrior.instructions:
print(i)
w = new_warriors[0]
mutated_warriors = asyncio.run(gpt.mutate_warrior_async([w], n_responses=4)).flatten() # get 4 mutations of warrior w
mutated_warriors = [w for w in mutated_warriors if w is not None and w.warrior is not None]
for w in mutated_warriors:
print('--------------------------------')
print(w.warrior)
print(w.llm_response)
for i in w.warrior.instructions:
print(i)It would output something like:
<Warrior name=Mirror Bomb 5 instructions>
```redcode
;redcode
;name Mirror Bomb
;author Creative Assistant
;strategy Bomb an opponent's code and mirror it around itself to confuse and trap.
;comments This warrior bombs instructions and then copies those bombs around itself in a mirrored fashion.
ORG start
step EQU 5 ; Step size for bombing and mirroring
target DAT.F #0, #0 ; pointer to current target for bombing
start ADD.AB #step, target ; move target pointer forward by step
MOV.AB #0, @target ; bomb the target instruction with DAT 0,0
MOV.F @target, target+step ; copy (mirror) the bombed code to position ahead
JMP.A start ; loop back to continue bombing
END
```redcode
<Warrior name=Mirror Bomb 5 instructions>
DAT.F # 0, # 0
ADD.AB # 5, $ -1
MOV.AB # 0, @ -2
MOV.F @ -3, $ 2
JMP.A $ -3, $ 0
python -m corewar.graphics --warriors ../../human_warriors/imp.red ../../human_warriors/dwarf.redHere is how to run the full DRQ algorithm:
cd src
python drq.py --seed=0 --save_dir="./drq_run_0/drq_seed=0" --n_processes=20 --resume=True --job_timeout=36000 --simargs.rounds=20 --simargs.size=8000 --simargs.cycles=80000 --simargs.processes=8000 --simargs.length=100 --simargs.distance=100 --timeout=900 --initial_opps "../human_warriors/imp.red" --n_rounds=20 --n_iters=250 --log_every=20 --last_k_opps=20 --sample_new_percent=0.1 --bc_axes="tsp,mc" --warmup_with_init_opps=True --warmup_with_past_champs=True --n_init=8 --n_mutate=1 --fitness_threshold=0.8 --single_cell=False --gpt_model="gpt-4.1-mini-2025-04-14" --temperature=1.0 --system_prompt="./prompts/system_prompt_0.txt" --new_prompt="./prompts/new_prompt_0.txt" --mutate_prompt="./prompts/mutate_prompt_0.txt"Coming soon!
Everything you need is already in this repo.
If, for some reason, you want to see more code and see what went into the experimentation that led to the creation of DRQ, then check out this repo.
To cite our work, you can use the following:
@article{kumar2025drq,
title = {Digital Red Queen: Adversarial Program Evolution in Core War with LLMs},
author = {Akarsh Kumar and Ryan Bahlous-Boldi and Prafull Sharma and Phillip Isola and Sebastian Risi and Yujin Tang and David Ha},
year = {2026},
url = {https://pub.sakana.ai/drq/}
}