This work corresponds to the ACM Transactions on Reconfigurable Technology and Systems Paper: https://dl.acm.org/doi/abs/10.1145/3567429
If you want to use this code please cite our paper:
@article{10.1145/3567429,
author = {Li, Carol Jingyi and Li, Xiangwei and Lou, Binglei and Jin, Craig T. and Boland, David and Leong, Philip H.W.},
title = {Fixed-Point FPGA Implementation of the FFT Accumulation Method for Real-Time Cyclostationary Analysis},
year = {2022},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
issn = {1936-7406},
url = {https://doi.org/10.1145/3567429},
doi = {10.1145/3567429},
abstract = {The spectral correlation density (SCD) is an important tool in cyclostationary signal detection and classification. Even using efficient techniques based on the fast Fourier transform (FFT), real-time implementations are challenging because of the high computational complexity. A key dimension for computational optimization lies in minimizing the wordlength employed. In this paper, we analyze the relationship between wordlength and signal-to-quantization noise in fixed-point implementations of the SCD function. A canonical SCD estimation algorithm, the FFT accumulation method (FAM) using fixed-point arithmetic is studied. We derive closed-form expressions for SQNR and compare them at wordlengths ranging from 14 to 26 bits. The differences between the calculated SQNR and bit-exact simulations are less than 1 dB. Furthermore, an HLS-based FPGA design is implemented on a Xilinx Zynq UltraScale+ XCZU28DR-2FFVG1517E RFSoC. Using less than 25% of the logic fabric on the device, it consumes 7.7 W total on-chip power and has a power efficiency of 12.4 GOPS/W, which is an order of magnitude improvement over an Nvidia Tesla K40 graphics processing unit (GPU) implementation. In terms of throughput, it achieves 50 MS/sec, which is a speedup of 1.6 over a recent optimized FPGA implementation.},
note = {Just Accepted},
journal = {ACM Trans. Reconfigurable Technol. Syst.},
month = {oct},
keywords = {FAM, HLS, SCD, FPGAs., quantization error}
}
and cite it using the following DOI: 10.5281/zenodo.7679339
Please also reference the included citation.cff file for more information.
Results of the paper can be reproduced from FAM_Synthesis/Figures
Run FAM_Synthesis/Figure/Result_sqnr.m

Run FAM_Synthesis/Figures/Result_check.m

Run FAM_Synthesis/Figures/Result_dsp.m

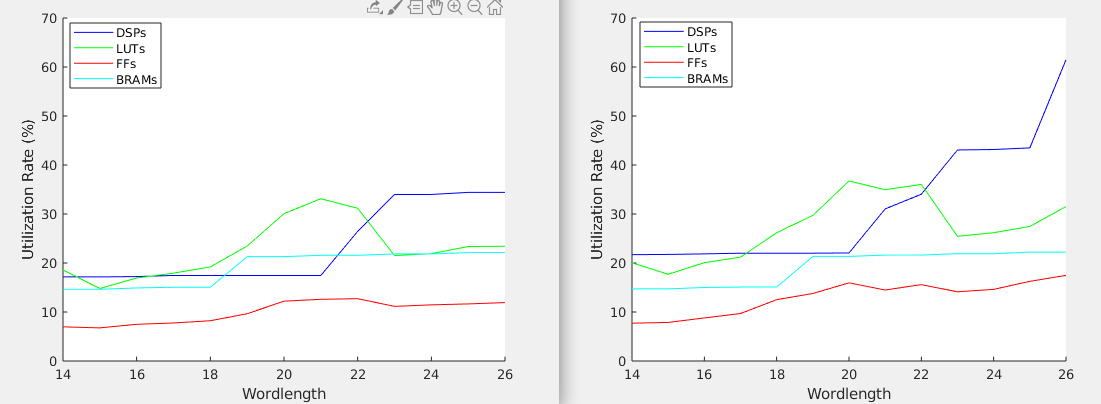
Run FAM_Synthesis/Figures/Result_utilize.m
Run FAM_Synthesis/Figures/Result_opti.m
