We have used data compression techniques namely Huffman coding, Shannon Fano and LZW (Lempel-Ziv-Welch) techniques. Using these we compress the strings to a smaller size in order to save space.
Table of contents 1)Acknowledgement 2)Introduction-data compression 3)Huffman coding 4)Shannon fano coding 5)Lempel ziv welch 6)Outputs of code
Introduction:
Data Compression: The process of encoding information using fewer units of storage than an un- encoded representation of data, through the use of specific encoding schemes. Data compression, or sometimes called source coding, is the process of converting input data into another data stream that has a smaller size, but retains the essential information contained within the original data stream.
Data Compression Implementations: Compression is useful because it helps reduce the consumption of resources, such as hard disk space or transmission bandwidth. With the interest and surge in environmental test data for the Surveillance Program, significant strains on computer storage resources will occur. Archiving of environmental test data from legacy systems, including data for the Environment Test lab. Familiar examples of data compressed files include .zip, rar, tar file extensions.
We have implemented three ways to compress the data-
- Huffman coding technique
- Shannon Fano coding technique
- Lempel-Ziv-Welch coding technique
Huffman coding Introduction: Huffman Coding is a technique of compressing data to reduce its size without losing any of the details. It was first developed by David Huffman. Huffman Coding is generally useful to compress the data in which there are frequently occurring characters. Using the Huffman Coding technique, we can compress the string to a smaller size.
-Algorithm for encoding Huffman coding first creates a tree using the frequencies of the character and then generates code for each character. Once the data is encoded, it has to be decoded. Decoding is done using the same tree. Huffman Coding prevents any ambiguity in the decoding process using the concept of prefix code ie. a code associated with a character should not be present in the prefix of any other code. The tree created above The tree created above helps in maintaining the property
-Algorithm for decoding To decode the encoded data we require the Huffman tree. We iterate through the binary encoded data. To find character corresponding to current bits, we use following simple steps.
- We start from root and do following until a leaf is found.
- If current bit is 0, we move to left node of the tree.
- If the bit is 1, we move to right node of the tree.
- If during traversal, we encounter a leaf node, we print character of that particular leaf node and then again continue the iteration of the encoded data starting from step 1. The below code takes a string as input, it encodes it and save in a variable encoded String. Then it decodes it and print the original string.
Shannon fano coding technique Introduction: Shannon Fano Algorithm is an entropy encoding technique for lossless data compression of multimedia. Named after Claude Shannon and Robert Fano, it assigns a code to each symbol based on their probabilities of occurrence. It is a variable-length encoding scheme, that is, the codes assigned to the symbols will be of varying length.
Algorithm for encoding The steps of the algorithm are as follows:
- Create a list of probabilities or frequency counts for the given set of symbols so that the relative frequency of occurrence of each symbol is known.
- Sort the list of symbols in decreasing order of probability, the most probable ones to the left and least probable to the right.
- Split the list into two parts, with the total probability of both the parts being as close to each other as possible
- Assign the value 0 to the left part and 1 to the right part. Repeat 3 and 4 for each subpart until the symbols are split into individual sub groups
Lempel-ziv-welch coding technique Introduction: The LZW algorithm is a very common compression technique. This algorithm is typically used in GIF and optionally in PDF and TIFF. Unix’s ‘compress’ command, among other uses. It is lossless, meaning no data is lost when compressing. The algorithm is simple to implement and has the potential for very high throughput in hardware implementations. It is the algorithm of the widely used Unix file compression utility compress and is used in the GIF image format.
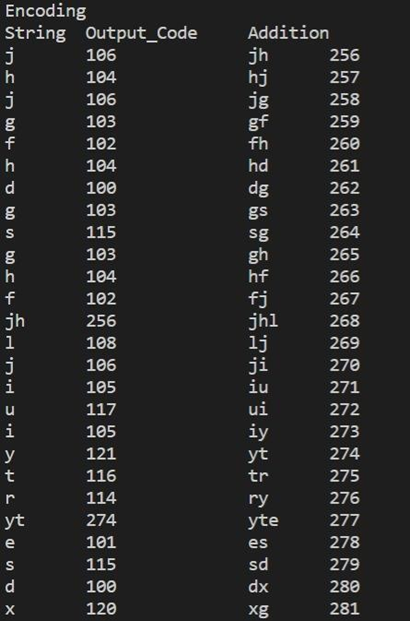
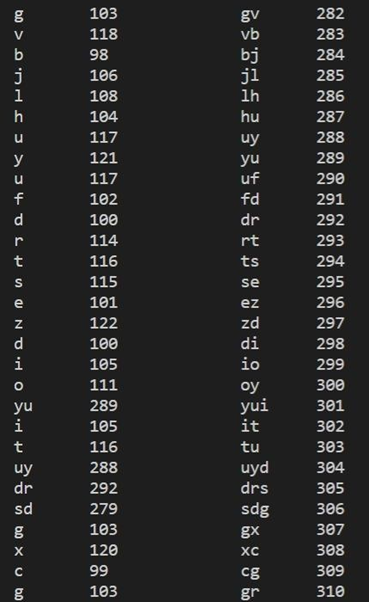
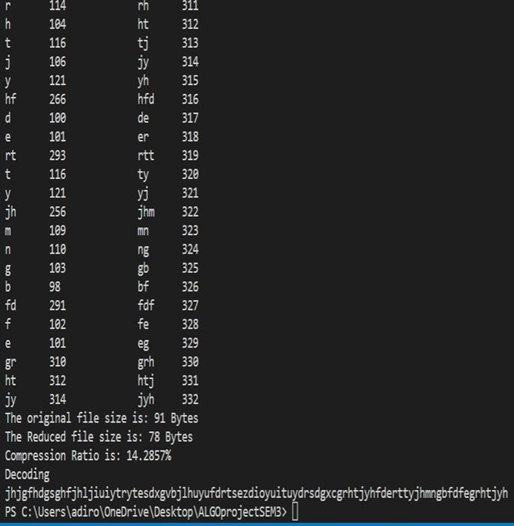
Encoding The idea of the compression algorithm is the following: as the input data is being processed, a dictionary keeps a correspondence between the longest encountered words and a list of code values. The words are replaced by their corresponding codes and so the input file is compressed. Therefore, the efficiency of the algorithm increases as the number of long, repetitive words in the input data increases.
Screenshots of output:
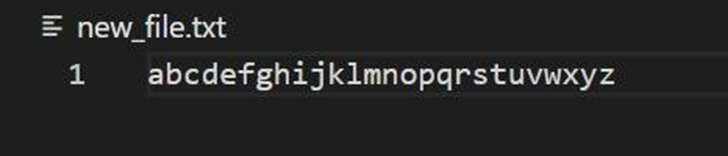
- Huffman coding input:
Hufffman encoding output:
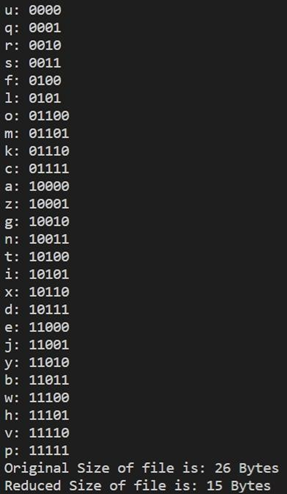
Huffman decoding:
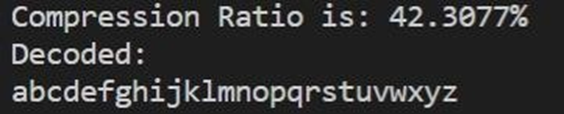
- Shannon Fano input:

Shannon Fano encoding:
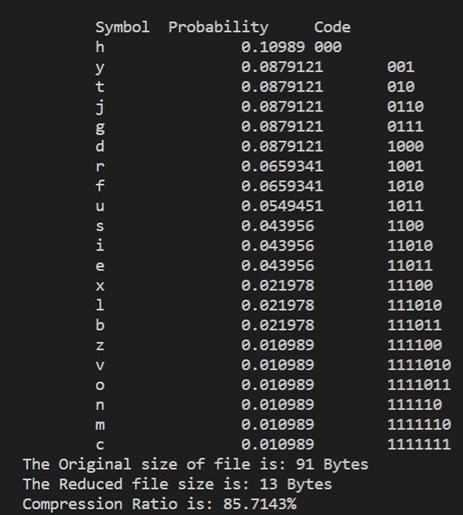
- LZW encoding input:

LZW encoding output