Close redis connections after executing #352
Conversation
web nodes have tendency of going zombie and as the result they get restarted regularly by uwsgi but --kill-on-term doesn't close the redis connections meaning they stay hanging and pile up if requests go high a bit. Bug: T263910
|
This seems overly coupled to the current way the class is used. We could merge this as an emergency workaround, let me know if you prefer to do that of course. The Redis(ScoreCache) class doesn't own its redis connect object, we should either fix how dependency injection is happening or have the caller close the connection. An example use case that will fail after this patch: looking up two scores from the cache. |
|
I 'll more or less echo @adamwight here. This feels weird to be honest. Closing the connection inside the As a side note, has the idea of setting |
Naja, that's not the case. The exec command checks for connections and if there is none, it'll establish a connection: https://github.com/andymccurdy/redis-py/blob/master/redis/client.py#L932 so it'll be slower but it wouldn't fail.
Yup, My best solution would to have a watchdog/heartbeat or something similar (plus having a proper transaction/rollback mechanism in place) but that's not possible without reworking half of ores. It'll be slower to re-initiate the connection but I don't think it would be too much, we recently made a lot of improvements in ores performance by putting most of requests it's making behind envoy (we might be able to do this here too, hitting appservers has been behind envoy for two months now)
I already made a patch for this a month ago: https://gerrit.wikimedia.org/r/633578 but given that ores spawn 60 different uwsgi process in one node, each one will have their own pool of connections and as the result I don't think it'll achieve the same effect (we can try that though). |
It's true that this isn't a particularly expensive connection so we might be ok with this. That being said, I still have the feeling that lowering the number of uwsgi workers and limiting them to a small number of connections (I am wondering tbh if anything >1 even makes sense due to the way ores uwsgi works) is a better approach than forcibly closing the connection at this level. As far as the envoy part goes, yes it does support redis in a pretty specific way (https://www.envoyproxy.io/docs/envoy/latest/intro/arch_overview/other_protocols/redis) but from my reading it looks like it can work quite fine for the cache. We could go down that way if the other approaches prove ineffective.
Yeah, I 've let a number of comments in the one too. I think we should try to go down that path and also try to cut down on the number of workers (they are too many anyway). |
|
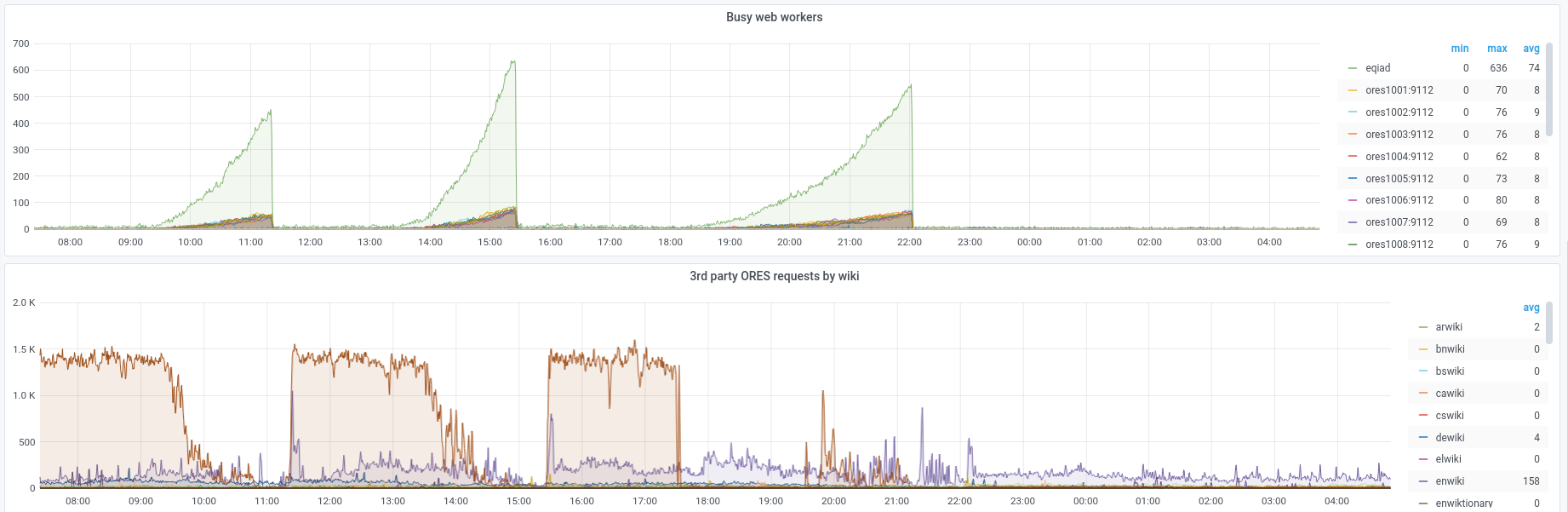
I definitely agree we should reduce number of uwsgi workers and also reduce max number of connections but if that doesn't fix the issue, let's try this method after that. My reasoning is that I'm not 100% sure uwsgi processes going zombie is all random. For example look this: https://grafana.wikimedia.org/d/HIRrxQ6mk/ores?orgId=1&from=1604474614257&to=1604551820888
It seems the third party requests to wikidata is being followed by the increase in number of zombie processes. Requests to wikidata triggers lots of errors if the edit is not done in main ns (meaning content is not parsable json). ores catches the error and respond properly: https://ores.wikimedia.org/v3/scores/wikidatawiki/17 but I can't shake off the feeling that the process goes zombie after that. |
|
The reason I'm depending on feeling on this is that ores observability is 13 out of 10. We should work on that later but I have no time for that. |
Merged the lowering of uwsgi workers already. Thanks!
Heh, that's an interesting observation. I am wondering whether it's indeed just correlation but not causation. Per you comment about ores catching it it shouldn't, I guess we can only know if we get a zombie uwsgi process and gdb it. Not sure how much it would pay off though |
web nodes have tendency of going zombie and as the result they get
restarted regularly by uwsgi but --kill-on-term doesn't close the redis
connections meaning they stay hanging and pile up if requests go high a
bit.
Bug: T263910